


python爬取音乐
# 免责声明 / Disclaimer
# 1. 本代码仅供学习Python编程及网络爬虫技术使用
# This code is for learning Python programming and web scraping only.
# 2. 使用者应对自身行为负责,遵守相关法律法规
# Users are responsible for their own actions and must comply with applicable laws.
# 3. 开发者不承担因滥用本代码导致的任何法律责任
# The developer is not liable for any legal consequences caused by misuse of this code.
# 4. 请勿将本代码或下载内容用于商业用途或侵犯他人权益
# Do not use this code or downloaded content for commercial purposes or to infringe on others' rights.
yinyue.py
import requests
from bs4 import BeautifulSoup
import re
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Referer": "https://music.163.com/"
}
def get_song_name(song_id):
"""获取歌曲名称"""
try:
url = f"https://music.163.com/song?id={song_id}"
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# 通过meta标签获取歌曲名
meta_tag = soup.find('meta', property='og:title')
return re.sub(r'[\\/*?:"<>|]', '_', meta_tag['content']) if meta_tag else song_id
except Exception as e:
print(f"获取名称失败 {song_id}: {str(e)}")
return song_id
def download_songs():
with open('yy.txt', 'r') as f:
song_ids = [id.strip() for id in f.readlines() if id.strip()]
for song_id in song_ids:
song_name = get_song_name(song_id)
print(f"正在下载: {song_name}.mp3")
url = f"http://music.163.com/song/media/outer/url?id={song_id}.mp3"
try:
response = requests.get(url, headers=headers, stream=True)
if response.status_code == 200:
with open(f"11/{song_name}.mp3", "wb") as f:
for chunk in response.iter_content(1024):
f.write(chunk)
else:
print(f"下载失败 {song_id},状态码:{response.status_code}")
except Exception as e:
print(f"下载异常 {song_id}: {str(e)}")
if __name__ == "__main__":
download_songs()yy.txt
2627478422
2675945374
2102115649
2101336370
1891879729
2664700941
1831766291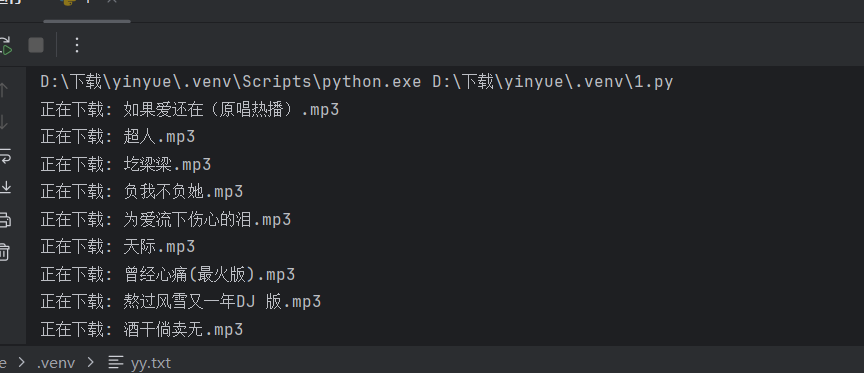


评论区